asc_copy_l12l0a
产 品 支 持 情 况
| 产 品 | 是 否 支 持 |
|---|---|
| √ | |
| √ |
功 能 说 明
用 于 搬 运 存 放 在L1 Buffer里 的512B大 小 的 矩 阵 到L0A Buffer里。包 含2D格 式 搬 运、3D格 式 搬 运。
函 数 原 型
高 维 切 分 搬 运2D格 式
C++__aicore__ inline void asc_copy_l12l0a(__ca__ int4b_t* dst, __cbuf__ int4b_t* src, uint16_t start_index, uint8_t repeat, uint16_t src_stride, uint16_t dst_gap) __aicore__ inline void asc_copy_l12l0a(__ca__ uint8_t* dst, __cbuf__ uint8_t* src, uint16_t start_index, uint8_t repeat, uint16_t src_stride, uint16_t dst_gap) __aicore__ inline void asc_copy_l12l0a(__ca__ int8_t* dst, __cbuf__ int8_t* src, uint16_t start_index, uint8_t repeat, uint16_t src_stride, uint16_t dst_gap) __aicore__ inline void asc_copy_l12l0a(__ca__ half* dst, __cbuf__ half* src, uint16_t start_index, uint8_t repeat, uint16_t src_stride, uint16_t dst_gap) __aicore__ inline void asc_copy_l12l0a(__ca__ bfloat16_t* dst, __cbuf__ bfloat16_t* src, uint16_t start_index, uint8_t repeat, uint16_t src_stride, uint16_t dst_gap) __aicore__ inline void asc_copy_l12l0a(__ca__ uint32_t* dst, __cbuf__ uint32_t* src, uint16_t start_index, uint8_t repeat, uint16_t src_stride, uint16_t dst_gap) __aicore__ inline void asc_copy_l12l0a(__ca__ int32_t* dst, __cbuf__ int32_t* src, uint16_t start_index, uint8_t repeat, uint16_t src_stride, uint16_t dst_gap) __aicore__ inline void asc_copy_l12l0a(__ca__ float* dst, __cbuf__ float* src, uint16_t start_index, uint8_t repeat, uint16_t src_stride, uint16_t dst_gap)同 步 高 维 切 分 搬 运2D格 式
C++__aicore__ inline void asc_copy_l12l0a_sync(__ca__ int4b_t* dst, __cbuf__ int4b_t* src, uint16_t start_index, uint8_t repeat, uint16_t src_stride, uint16_t dst_gap) __aicore__ inline void asc_copy_l12l0a_sync(__ca__ uint8_t* dst, __cbuf__ uint8_t* src, uint16_t start_index, uint8_t repeat, uint16_t src_stride, uint16_t dst_gap) __aicore__ inline void asc_copy_l12l0a_sync(__ca__ int8_t* dst, __cbuf__ int8_t* src, uint16_t start_index, uint8_t repeat, uint16_t src_stride, uint16_t dst_gap) __aicore__ inline void asc_copy_l12l0a_sync(__ca__ half* dst, __cbuf__ half* src, uint16_t start_index, uint8_t repeat, uint16_t src_stride, uint16_t dst_gap) __aicore__ inline void asc_copy_l12l0a_sync(__ca__ bfloat16_t* dst, __cbuf__ bfloat16_t* src, uint16_t start_index, uint8_t repeat, uint16_t src_stride, uint16_t dst_gap) __aicore__ inline void asc_copy_l12l0a_sync(__ca__ uint32_t* dst, __cbuf__ uint32_t* src, uint16_t start_index, uint8_t repeat, uint16_t src_stride, uint16_t dst_gap) __aicore__ inline void asc_copy_l12l0a_sync(__ca__ int32_t* dst, __cbuf__ int32_t* src, uint16_t start_index, uint8_t repeat, uint16_t src_stride, uint16_t dst_gap) __aicore__ inline void asc_copy_l12l0a_sync(__ca__ float* dst, __cbuf__ float* src, uint16_t start_index, uint8_t repeat, uint16_t src_stride, uint16_t dst_gap)高 维 切 分 搬 运3D格 式
C++__aicore__ inline void asc_copy_l12l0a(__ca__ int4b_t* dst, __cbuf__ int4b_t* src, uint16_t k_extension, uint16_t m_extension, uint16_t k_start_pt, uint16_t m_start_pt, uint8_t stride_w, uint8_t stride_h, uint8_t filter_w, uint8_t filter_h, uint8_t dilation_filter_w, uint8_t dilation_filter_h, bool filter_size_w, bool filter_size_h, bool transpose, bool f_matrix_ctrl, uint16_t channel_size) __aicore__ inline void asc_copy_l12l0a(__ca__ uint8_t* dst, __cbuf__ uint8_t* src, uint16_t k_extension, uint16_t m_extension, uint16_t k_start_pt, uint16_t m_start_pt, uint8_t stride_w, uint8_t stride_h, uint8_t filter_w, uint8_t filter_h, uint8_t dilation_filter_w, uint8_t dilation_filter_h, bool filter_size_w, bool filter_size_h, bool transpose, bool f_matrix_ctrl, uint16_t channel_size) __aicore__ inline void asc_copy_l12l0a(__ca__ int8_t* dst, __cbuf__ int8_t* src, uint16_t k_extension, uint16_t m_extension, uint16_t k_start_pt, uint16_t m_start_pt, uint8_t stride_w, uint8_t stride_h, uint8_t filter_w, uint8_t filter_h, uint8_t dilation_filter_w, uint8_t dilation_filter_h, bool filter_size_w, bool filter_size_h, bool transpose, bool f_matrix_ctrl, uint16_t channel_size) __aicore__ inline void asc_copy_l12l0a(__ca__ half* dst, __cbuf__ half* src, uint16_t k_extension, uint16_t m_extension, uint16_t k_start_pt, uint16_t m_start_pt, uint8_t stride_w, uint8_t stride_h, uint8_t filter_w, uint8_t filter_h, uint8_t dilation_filter_w, uint8_t dilation_filter_h, bool filter_size_w, bool filter_size_h, bool transpose, bool f_matrix_ctrl, uint16_t channel_size) __aicore__ inline void asc_copy_l12l0a(__ca__ bfloat16_t* dst, __cbuf__ bfloat16_t* src, uint16_t k_extension, uint16_t m_extension, uint16_t k_start_pt, uint16_t m_start_pt, uint8_t stride_w, uint8_t stride_h, uint8_t filter_w, uint8_t filter_h, uint8_t dilation_filter_w, uint8_t dilation_filter_h, bool filter_size_w, bool filter_size_h, bool transpose, bool f_matrix_ctrl, uint16_t channel_size) __aicore__ inline void asc_copy_l12l0a(__ca__ uint32_t* dst, __cbuf__ uint32_t* src, uint16_t k_extension, uint16_t m_extension, uint16_t k_start_pt, uint16_t m_start_pt, uint8_t stride_w, uint8_t stride_h, uint8_t filter_w, uint8_t filter_h, uint8_t dilation_filter_w, uint8_t dilation_filter_h, bool filter_size_w, bool filter_size_h, bool transpose, bool f_matrix_ctrl, uint16_t channel_size) __aicore__ inline void asc_copy_l12l0a(__ca__ int32_t* dst, __cbuf__ int32_t* src, uint16_t k_extension, uint16_t m_extension, uint16_t k_start_pt, uint16_t m_start_pt, uint8_t stride_w, uint8_t stride_h, uint8_t filter_w, uint8_t filter_h, uint8_t dilation_filter_w, uint8_t dilation_filter_h, bool filter_size_w, bool filter_size_h, bool transpose, bool f_matrix_ctrl, uint16_t channel_size) __aicore__ inline void asc_copy_l12l0a(__ca__ float* dst, __cbuf__ float* src, uint16_t k_extension, uint16_t m_extension, uint16_t k_start_pt, uint16_t m_start_pt, uint8_t stride_w, uint8_t stride_h, uint8_t filter_w, uint8_t filter_h, uint8_t dilation_filter_w, uint8_t dilation_filter_h, bool filter_size_w, bool filter_size_h, bool transpose, bool f_matrix_ctrl, uint16_t channel_size)同 步 高 维 切 分 搬 运3D格 式
C++__aicore__ inline void asc_copy_l12l0a_sync(__ca__ int4b_t* dst, __cbuf__ int4b_t* src, uint16_t k_extension, uint16_t m_extension, uint16_t k_start_pt, uint16_t m_start_pt, uint8_t stride_w, uint8_t stride_h, uint8_t filter_w, uint8_t filter_h, uint8_t dilation_filter_w, uint8_t dilation_filter_h, bool filter_size_w, bool filter_size_h, bool transpose, bool f_matrix_ctrl, uint16_t channel_size) __aicore__ inline void asc_copy_l12l0a_sync(__ca__ uint8_t* dst, __cbuf__ uint8_t* src, uint16_t k_extension, uint16_t m_extension, uint16_t k_start_pt, uint16_t m_start_pt, uint8_t stride_w, uint8_t stride_h, uint8_t filter_w, uint8_t filter_h, uint8_t dilation_filter_w, uint8_t dilation_filter_h, bool filter_size_w, bool filter_size_h, bool transpose, bool f_matrix_ctrl, uint16_t channel_size) __aicore__ inline void asc_copy_l12l0a_sync(__ca__ int8_t* dst, __cbuf__ int8_t* src, uint16_t k_extension, uint16_t m_extension, uint16_t k_start_pt, uint16_t m_start_pt, uint8_t stride_w, uint8_t stride_h, uint8_t filter_w, uint8_t filter_h, uint8_t dilation_filter_w, uint8_t dilation_filter_h, bool filter_size_w, bool filter_size_h, bool transpose, bool f_matrix_ctrl, uint16_t channel_size) __aicore__ inline void asc_copy_l12l0a_sync(__ca__ half* dst, __cbuf__ half* src, uint16_t k_extension, uint16_t m_extension, uint16_t k_start_pt, uint16_t m_start_pt, uint8_t stride_w, uint8_t stride_h, uint8_t filter_w, uint8_t filter_h, uint8_t dilation_filter_w, uint8_t dilation_filter_h, bool filter_size_w, bool filter_size_h, bool transpose, bool f_matrix_ctrl, uint16_t channel_size) __aicore__ inline void asc_copy_l12l0a_sync(__ca__ bfloat16_t* dst, __cbuf__ bfloat16_t* src, uint16_t k_extension, uint16_t m_extension, uint16_t k_start_pt, uint16_t m_start_pt, uint8_t stride_w, uint8_t stride_h, uint8_t filter_w, uint8_t filter_h, uint8_t dilation_filter_w, uint8_t dilation_filter_h, bool filter_size_w, bool filter_size_h, bool transpose, bool f_matrix_ctrl, uint16_t channel_size) __aicore__ inline void asc_copy_l12l0a_sync(__ca__ uint32_t* dst, __cbuf__ uint32_t* src, uint16_t k_extension, uint16_t m_extension, uint16_t k_start_pt, uint16_t m_start_pt, uint8_t stride_w, uint8_t stride_h, uint8_t filter_w, uint8_t filter_h, uint8_t dilation_filter_w, uint8_t dilation_filter_h, bool filter_size_w, bool filter_size_h, bool transpose, bool f_matrix_ctrl, uint16_t channel_size) __aicore__ inline void asc_copy_l12l0a_sync(__ca__ int32_t* dst, __cbuf__ int32_t* src, uint16_t k_extension, uint16_t m_extension, uint16_t k_start_pt, uint16_t m_start_pt, uint8_t stride_w, uint8_t stride_h, uint8_t filter_w, uint8_t filter_h, uint8_t dilation_filter_w, uint8_t dilation_filter_h, bool filter_size_w, bool filter_size_h, bool transpose, bool f_matrix_ctrl, uint16_t channel_size) __aicore__ inline void asc_copy_l12l0a_sync(__ca__ float* dst, __cbuf__ float* src, uint16_t k_extension, uint16_t m_extension, uint16_t k_start_pt, uint16_t m_start_pt, uint8_t stride_w, uint8_t stride_h, uint8_t filter_w, uint8_t filter_h, uint8_t dilation_filter_w, uint8_t dilation_filter_h, bool filter_size_w, bool filter_size_h, bool transpose, bool f_matrix_ctrl, uint16_t channel_size)
参 数 说 明
表1 2D格 式 参 数 说 明
| 参 数 名 | 输 入/输 出 | 描 述 |
|---|---|---|
| dst | 输 出 | 目 的L0A Buffer地 址。 |
| src | 输 入 | 源L1 Buffer地 址。 |
| start_index | 输 入 | 分 形 矩 阵ID,说 明 搬 运 起 始 位 置 为 源 操 作 数 中 第 几 个 分 形(0为 源 操 作 数 中 第1个 分 形 矩 阵)。取 值 范 围:[0, 65535]。单 位 为512字 节。 |
| repeat | 输 入 | 迭 代 次 数,每 个 迭 代 可 以 处 理512B数 据。取 值 范 围:[1, 255]。 |
| src_stride | 输 入 | 相 邻 迭 代 间,源 操 作 数 前 一 个 分 形 与 后 一 个 分 型 起 始 地 址 的 间 隔。取 值 范 围:[0, 65535]。单 位 为512字 节。 |
| dst_gap | 输 入 | 目 的 操 作 数 相 邻 连 续 数 据 块 的 间 隔(前 面 一 个 数 据 块 的 尾 与 后 面 一 个 数 据 块 的 头 的 间 隔)。取 值 范 围:[0, 65535]。单 位 为512字 节。 |
表2 3D格 式 参 数 说 明
| 参 数 名 | 输 入/输 出 | 描 述 |
|---|---|---|
| dst | 输 出 | 目 的L0A Buffer地 址。 |
| src | 输 入 | 源L1 Buffer地 址。 |
| k_extension | 输 入 | 该 指 令 在 目 的 操 作 数width维 度 的 传 输 长 度。如 果 不 覆 盖 最 右 侧 的 分 形,对 于half类 型,应 为16的 倍 数,对 于int8_t/uint8_t类 型,应 为32的 倍 数;如 果 覆 盖 最 右 侧 的 分 形,则 无 倍 数 要 求。取 值 范 围:[1, 65535]。 |
| m_extension | 输 入 | 该 指 令 在 目 的 操 作 数height维 度 的 传 输 长 度。如 果 不 覆 盖 最 下 侧 的 分 形,对 于half/int8_t/uint8_t类 型,应 为16的 倍 数;如 果 覆 盖 最 下 侧 的 分 形,则 无 倍 数 要 求。取 值 范 围:[1, 65535]。 |
| k_start_pt | 输 入 | 该 指 令 在 目 的 操 作 数width维 度 的 起 点。对 于half类 型,应 为16的 倍 数,对 于int8_t/uint8_t类 型,应 为32的 倍 数。取 值 范 围:[0, 65535] |
| m_start_pt | 输 入 | 该 指 令 在 目 的 操 作 数height维 度 的 起 点,如 果 不 覆 盖 最 下 侧 的 分 形,对 于half/int8_t/uint8_t,应 为16的 倍 数;如 果 覆 盖 最 下 侧 的 分 形,则 无 倍 数 要 求。取 值 范 围:[0, 65535]。 |
| stride_w | 输 入 | 卷 积 核 在 源 操 作 数width维 度 滑 动 的 步 长,取 值 范 围:[1, 63]。 |
| stride_h | 输 入 | 卷 积 核 在 源 操 作 数height维 度 滑 动 的 步 长,取 值 范 围:[1, 63]。 |
| filter_w | 输 入 | 卷 积 核width,取 值 范 围:[1, 255]。 |
| filter_h | 输 入 | 卷 积 核height,取 值 范 围:[1, 255]。 |
| dilation_filter_w | 输 入 | 卷 积 核width膨 胀 系 数,取 值 范 围:[1, 255]。 |
| dilation_filter_h | 输 入 | 卷 积 核height膨 胀 系 数,取 值 范 围:[1, 255]。 |
| filter_size_w | 输 入 | 是 否 在filter_w的 基 础 上 将 卷 积 核width增 加256个 元 素。true表 示 增 加;false表 示 不 增 加。 |
| filter_size_h | 输 入 | 是 否 在filter_h的 基 础 上 将 卷 积 核height增 加256个 元 素。true表 示 增 加;false表 示 不 增 加。 |
| transpose | 输 入 | 是 否 启 用 转 置 功 能,对 整 个 目 标 矩 阵 进 行 转 置,仅 在 源 操 作 数 为half类 型 时 有 效。true表 示 启 用;false表 示 不 启 用。 |
| f_matrix_ctrl | 输 入 | 表 示asc_copy_l12l0a指 令 从 左 矩 阵 还 是 右 矩 阵 获 取FeatureMap的 属 性 描 述,当 前 只 支 持 设 置 为false。 |
| channel_size | 输 入 | 源 操 作 数 的 通 道 数,取 值 范 围:[1, 63]。对 于uint32_t/int32_t/float,channelSize可 取 值 为4,N * 8,N * 8 + 4;对 于half/bfloat16,channelSize可 取 值 为4,8,N * 16,N * 16 + 4,N * 16 + 8;对 于int8_t/uint8_t,channelSize可 取 值 为4,8,16, 32 * N,N * 32 + 4,N * 32 + 8,N * 32 + 16;对 于int4b_t,ChannelSize可 取 值 为8,16,32,N * 64,N * 64 + 8,N * 64 + 16,N * 64 + 32。N为 正 整 数。 |
返 回 值 说 明
无
流 水 类 型
PIPE_MTE1
约 束 说 明
- dst的 起 始 地 址 需 要512字 节 对 齐,src的 起 始 地 址 需 要32字 节 对 齐。
- 本 接 口 不 支 持2D格 式 搬 运 的 转 置 场 景。
3D数 据 格 式 说 明
要 求 输 入 的feature map和filter的 格 式 是NC1HWC0,其 中C0是 最 低 维 度 而 且C0是 固 定 值 为16(对 于u8/s8类 型 为32),C1=C/C0。
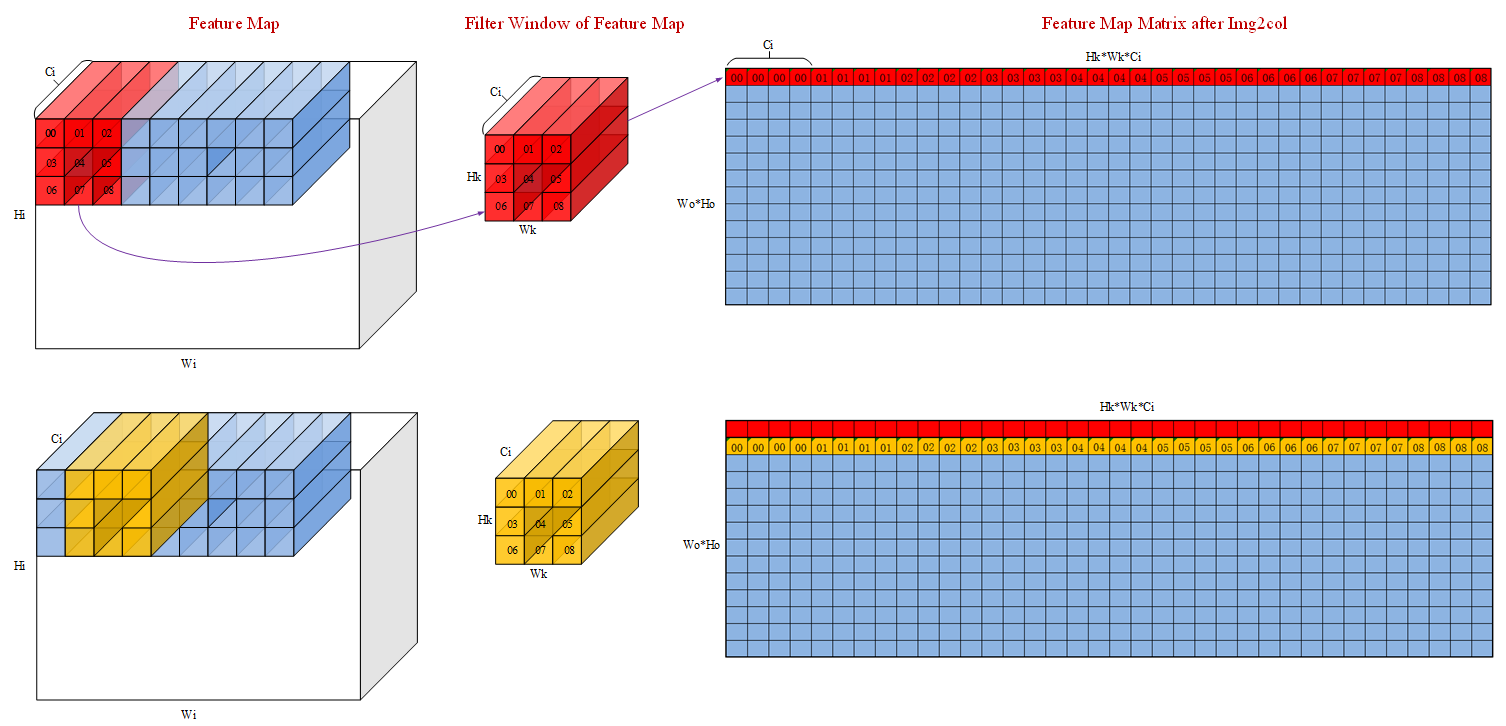
为 了 简 化 场 景,以 下 场 景 假 设 输 入 的feature map的channel为4,即Ci=4。输 入feature maps 在A1中 的 形 状 为(Hi,Wi,Ci),经 过load3dv1处 理 后 在A2 的 数 据 形 状 为(WoHo, HkWk*Ci)。其 中Wo和Ho是 卷 积 后 输 出 的shape,Hk和Wk是filter的shape。
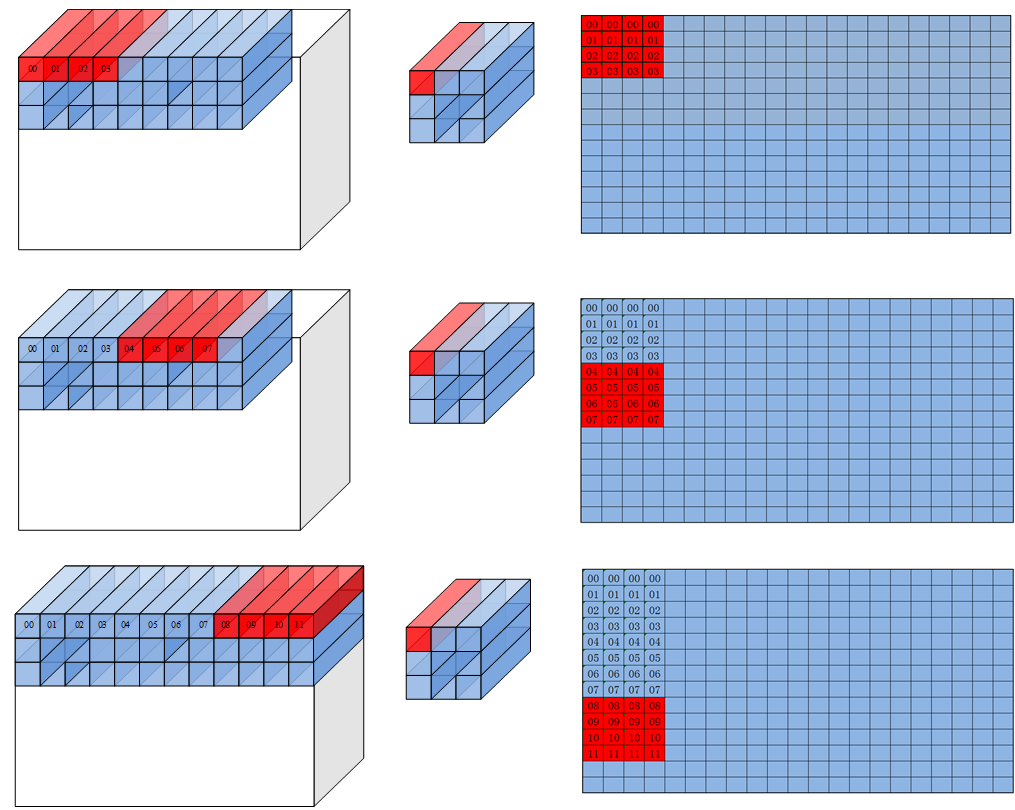
直 观 的 来 看,img2col的 过 程 就 是filter在feature map上 扫 过,将 对 应feature map的 数 据 展 开 成 输 出 数 据 的 每 一 行 的 过 程。filter首 先 在W方 向 上 滑 动Wo步,然 后 在H方 向 上 走 一 步 然 后 重 复 以 上 过 程,最 终 输 出Wo * Ho行 数 据。下 图 中 红 色 和 黄 色 的 数 据 分 别 代 表 第 一 行 和 第 二 行。数 字 表 示 原 始 输 入 数 据,filter和 输 出 数 据 三 者 之 间 的 关 联 关 系。可 以 看 到,load3dv1首 先 在 输 入 数 据 的Ci维 度 搬 运 对 应 于00的4个 数,然 后 搬 运 对 应 于01的 四 个 数,最 终 这 一 行 的 大 小 为HkWkCi即334=36个 数。
- 对 应 的feature map格 式 如 下 图:
- 对 应 的filter的 格 式 如 下 图:
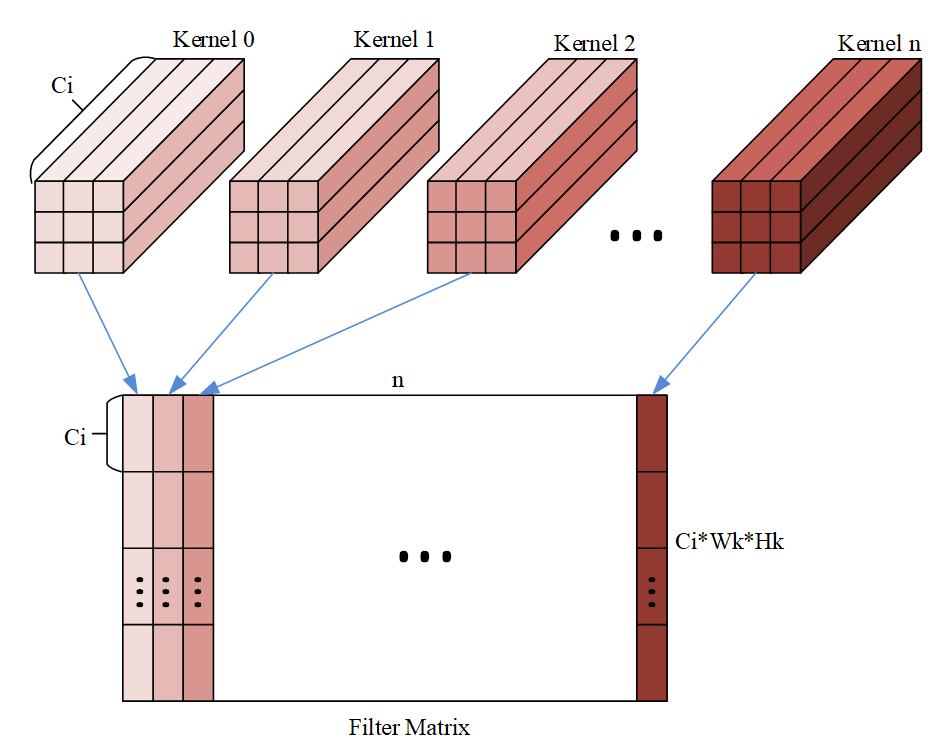
其 中n为filter的 个 数,可 以 看 出 维 度 排 布 为(Hk,Wk,Ci,n),但 是 需 要 注 意 的 是 下 图 的 格 式 还 需 要 根 据Mmad中B矩 阵 的 格 式 转 换。
实 际 操 作 中,由 于 存 储 空 间 或 者 计 算 能 力 限 制,我 们 通 常 会 将 整 个 卷 积 计 算 分 块,一 次 只 搬 运 并 计 算 一 小 块 数 据。
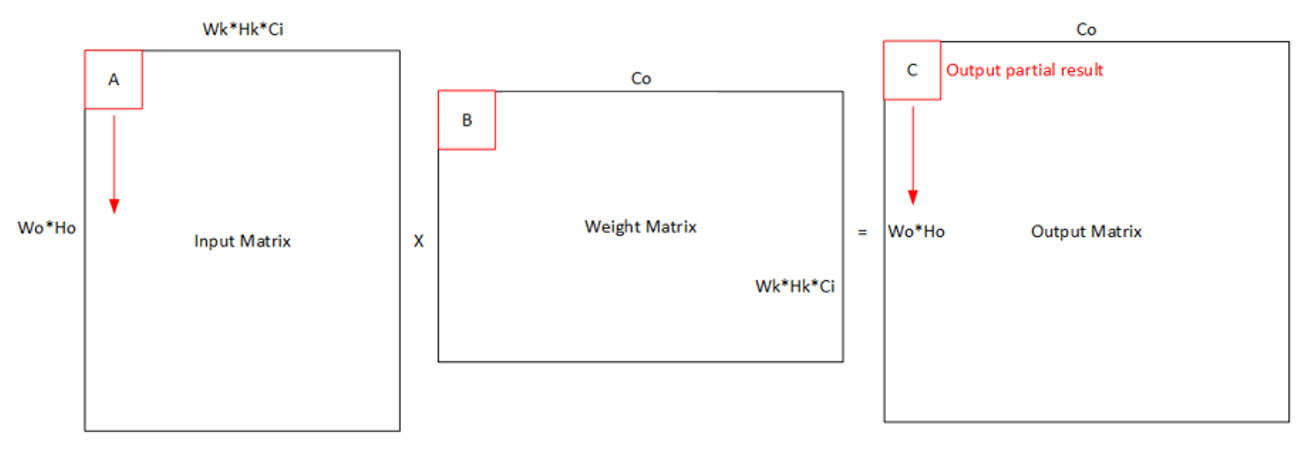
对 于A2 的feature map来 说 有 两 种 方 案,水 平 分 块 和 垂 直 分 块。分 别 对 应 参 数 中repeatMode的0和1。
注:下 图 中 的 分 形 矩 阵 大 小 为4x4,实 际 应 该 为16x16 (对 于u8/s8类 型 为16x32)
repeatMode =0时,每 次repeat会 改 变 在filter窗 口 中 读 取 数 据 点 的 位 置,然 后 跳 到 下 一 个C0的 位 置。
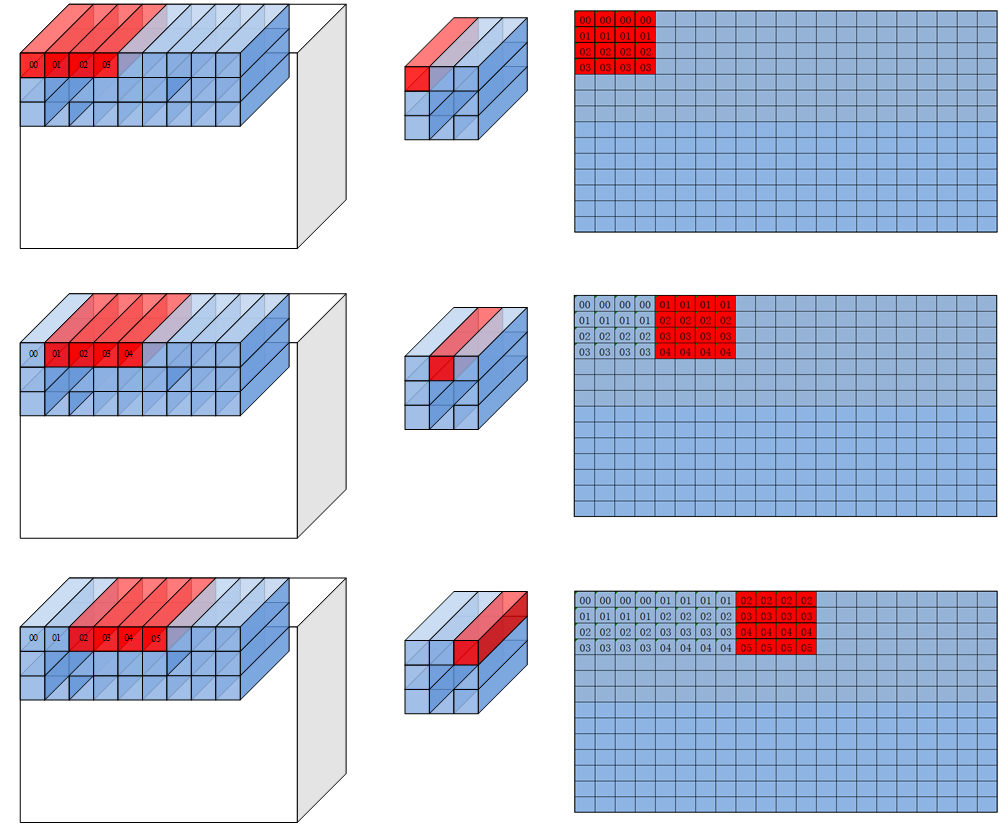
repeatMode =1的 时 候filter窗 口 中 读 取 数 据 的 位 置 保 持 不 变,每 个repeat在feature map中 前 进C0个 元 素。
调 用 示 例
__cbuf__ half src[256];
__ca__ half dst[256];
asc_copy_l12l0a(dst, src, 1, 1, 1, 0);