Sort32
产 品 支 持 情 况
功 能 说 明
头 文 件 路 径 为:"basic_api/kernel_operator_proposal_intf.h"
Sort32接 口 实 现 一 次 迭 代 内 对32个 数 的 降 序 排 列 操 作。
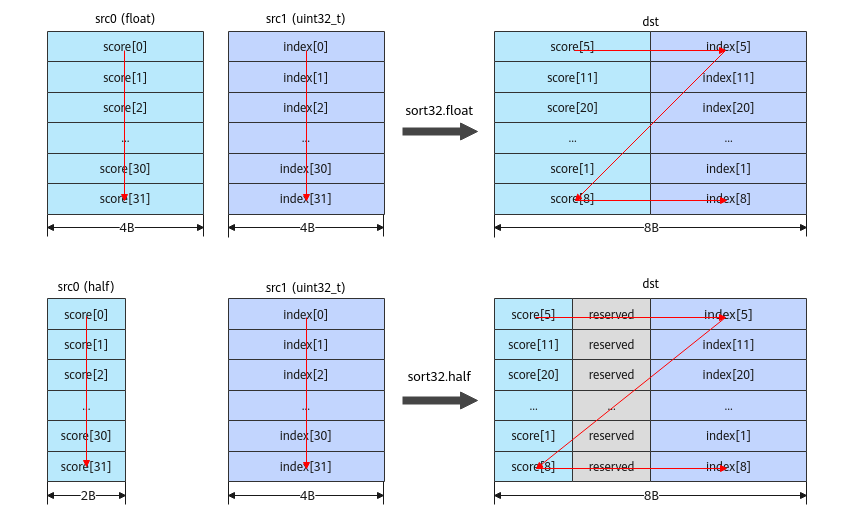
如 下 图 所 示,src0和src1分 别 表 示 待 排 序 的 数 据score和 对 应RP的 索 引index,排 序 完 成 后 以(score, index)的 结 构 存 储 在dst中。
src1固 定 为uint32_t类 型,无 论src0是float还 是half类 型,dst中 的(score, index)结 构 总 是 占 据8B空 间。其 中:
- 当src0为float类 型 时,dst中 的index存 储 在 高4B,score存 储 在 低4B;
- 当src0为half类 型 时,dst中index存 储 在 高4B,score存 储 在 低2B,中 间 的2B保 留。
图 1 Sort32排 序 示 意 图
函 数 原 型
C++
template <typename T>
__aicore__ inline void Sort32(const LocalTensor<T>& dst, const LocalTensor<T>& src0, const LocalTensor<uint32_t>& src1, const int32_t repeatTime)
参 数 说 明
表1 模 板 参 数 说 明
| 参 数 名 | 描 述 |
|---|---|
| T | 操 作 数 数 据 类 型。 |
表2 参 数 说 明
| 参 数 名 称 | 输 入/输 出 | 说 明 |
|---|---|---|
| dst | 输 出 | 目 的 操 作 数。 类 型 为LocalTensor,支 持 的TPosition为VECIN/VECCALC/VECOUT LocalTensor的 起 始 地 址 需 要32字 节 对 齐。 |
| src0 | 输 入 | 源 操 作 数。 类 型 为LocalTensor,支 持 的TPosition为VECIN/VECCALC/VECOUT LocalTensor的 起 始 地 址 需 要32字 节 对 齐。 |
| src1 | 输 入 | 源 操 作 数。 类 型 为LocalTensor,支 持 的TPosition为VECIN/VECCALC/VECOUT LocalTensor的 起 始 地 址 需 要32字 节 对 齐。 注:src1的 数 据 类 型 固 定 为uint32_t。 |
| repeatTime | 输 入 | 重 复 迭 代 次 数。每 次 迭 代 完 成32个 元 素 的 排 序,下 次 迭 代src0跳 过128B空 间,src1跳 过128B空 间,dst跳 过256B空 间。每 次 迭 代 输 入src0要 求128B对 齐,src1要 求128B对 齐,输 出dst要 求256B对 齐。repeatTime∈[0, 255]。 注:repeatTime = 0表 示 不 执 行 排 序,该 接 口 将 被 视 为NOP(空 操 作)。 |
数 据 类 型
表3 数 据 类 型 组 合 情 况
| src0数 据 类 型 | src1数 据 类 型 | dst数 据 类 型 |
|---|---|---|
| half | uint32_t | half |
| float | uint32_t | float |
约 束 说 明
- 地 址 对 齐 约 束 参 考通 用 地 址 对 齐 约 束。
- repeatTime = 0表 示 不 执 行 排 序,该 接 口 将 被 视 为NOP(空 操 作)。
- 如 果 存 在score[i]==score[j]并 且i>j,将 优 先 选 取score[j]排 在 前 面。
- 每 次 迭 代 内 的 数 据 会 进 行 排 序,不 同 迭 代 间 的 数 据 不 会 进 行 排 序。
- 每 次 迭 代 输 入src0要 求128B(float)/64B(half)对 齐,src1要 求128B对 齐,输 出dst要 求256B对 齐。
调 用 示 例
完 整 示 例 请 参 考Sort32样 例。
C++
AscendC::LocalTensor<float> srcLocal0 = inQueueSrc0.DeQue<float>();
AscendC::LocalTensor<uint32_t> srcLocal1 = inQueueSrc1.DeQue<uint32_t>();
AscendC::LocalTensor<float> dstLocal = outQueueDst.AllocTensor<float>();
// repeatTime = 4, 对128个 数 分 成4组 进 行 排 序,每 次 完 成1组32个 数 的 排 序
AscendC::Sort32<float>(dstLocal, srcLocal0, srcLocal1, 4);
outQueueDst.EnQue<float>(dstLocal);
inQueueSrc0.FreeTensor(srcLocal0);
inQueueSrc1.FreeTensor(srcLocal1);