随 路 量 化 激 活 搬 运
产 品 支 持 情 况
功 能 说 明
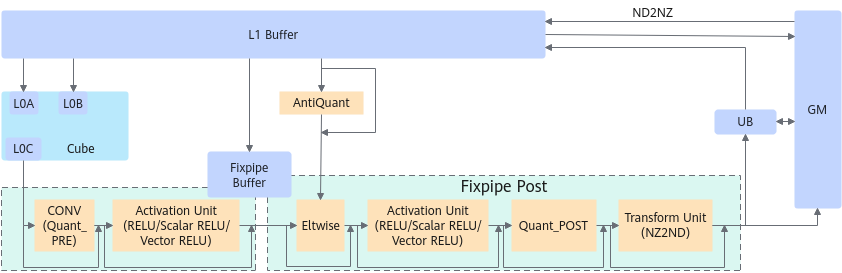
支 持 在 数 据 搬 运 过 程 中 进 行 量 化 和Relu激 活 等 操 作,同 时 支 持Local Memory到Global Memory通 路NZ到ND格 式 的 转 换。
函 数 原 型
Local Memory -> Global Memory,支 持 量 化 和Relu激 活 等 操 作,同 时 支 持NZ到ND格 式 的 转 换
Texttemplate <typename T, typename U> __aicore__ inline void DataCopy(const GlobalTensor<T>& dst, const LocalTensor<U>& src, const DataCopyCO12DstParams& intriParams)Local Memory -> Local Memory,支 持 量 化 和Relu激 活 等 操 作
Texttemplate <typename T, typename U> __aicore__ inline void DataCopy(const LocalTensor<T>& dst, const LocalTensor<U>& src, const DataCopyCO12DstParams& intriParams)
说 明
各 原 型 支 持 的 具 体 数 据 通 路 和 数 据 类 型,请 参 考支 持 的 通 路 和 数 据 类 型。
参 数 说 明
表 1 模 板 参 数 说 明
目 的 操 作 数 的 数 据 类 型。支 持 的 数 据 类 型 请 参 考支 持 的 通 路 和 数 据 类 型。 | |
源 操 作 数 的 数 据 类 型。支 持 的 数 据 类 型 请 参 考支 持 的 通 路 和 数 据 类 型。 |
表 2 参 数 说 明
搬 运 参 数,类 型 为DataCopyCO12DstParams。 具 体 定 义 请 参 考${INSTALL_DIR}/include/ascendc/basic_api/interface/kernel_struct_data_copy.h,${INSTALL_DIR}请 替 换 为CANN软 件 安 装 后 文 件 存 储 路 径。 |
表 3 DataCopyCO12DstParams结 构 体 参 数 定 义(C0取 值:一 般 情 况 下,C0 = 16;开 启channelSplit(channel切 分)时,C0 = 8)
| |
| |
| |
用 于 控 制 量 化 模 式,QuantMode_t类 型,具 体 定 义 如 下。默 认 值 为QuantMode_t::NoQuant,即 不 开 启 量 化 功 能。 配 置 为scalar量 化 时,需 要 调 用SetFixpipePreQuantFlag接 口 来 设 置scalar量 化 参 数;配 置 为tensor量 化 时,需 要 调 用SetFixPipeConfig来 设 置tensor量 化 参 数。 enum QuantMode_t
{
NoQuant, // 不 开 启 量 化 功 能
F322F16, // float cast成half,cast mode为CAST_RINT模 式
F322BF16, // float cast成bfloat16_t,cast mode为CAST_RINT模 式
DEQF16, // int32_t量 化 成half, scalar量 化
VDEQF16, // int32_t量 化 成half,tensor量 化
QF322B8_PRE, // float量 化 成int8_t/uint8_t,scalar量 化
VQF322B8_PRE, // float量 化 成int8_t/uint8_t,tensor量 化
REQ8, // int32_t量 化 成int8_t/uint8_t,scalar量 化
VREQ8, // int32_t量 化 成int8_t/uint8_t,tensor量 化
}; | |
用 于 配 置relu操 作 的 模 式,类 型 为uint8_t,取 值 如 下:
| |
类 型 为bool,配 置 是 否 开 启channel切 分,对 于float类 型 的dst生 效。
| |
类 型 为bool,配 置 是 否 开 启NZ2ND的 格 式 转 换,仅 在CO1 -> GM通 路 生 效。 如 果 要 开 启NZ2ND的 功 能 需 要 同 步 调 用SetFixpipeNz2ndFlag来 设 置 格 式 转 换 的 相 关 配 置 信 息。
| |
用 于 配 置 是 否 开 启ClipRelu操 作,参 数 类 型 为uint8_t,取 值 如 下:0,不 开 启ClipRelu;1,开 启ClipRelu,此 时 需 要 调 用SetFixPipeClipRelu来 设 置clipRelu的 最 大 值。 | |
用 于 配 置 是 否 开 启Elementwise操 作 及 操 作 模 式。Elementwise操 作 是 指 进 行 随 路 量 化 后,可 以 逐 个 元 素 加/减 一 个LocalTensor,大 小 为mSize * nSize,具 体LocalTensor地 址 相 关 参 数 需 要 调 用SetFixPipeAddr来 设 置。 eltWiseOp参 数 类 型 为uint8_t,取 值 如 下:
| |
unitFlag是 一 种Mmad指 令 和Fixpipe指 令 细 粒 度 的 并 行 功 能,使 能 该 功 能 后,硬 件 每 计 算 完 一 个 分 形,计 算 结 果 就 会 被 搬 出。取 值 说 明 如 下:
| |
返 回 值 说 明
无
约 束 说 明
无
支 持 的 通 路 和 数 据 类 型
下 文 的 数 据 通 路 均 通 过 逻 辑 位 置TPosition来 表 达,并 注 明 了 对 应 的 物 理 通 路。TPosition与 物 理 内 存 的 映 射 关 系 见表1。
表 4 Local Memory -> Global Memory具 体 通 路 和 支 持 的 数 据 类 型
表 5 Local Memory -> Local Memory具 体 通 路 和 支 持 的 数 据 类 型
调 用 示 例
随 路 格 式 转 换 数 据 搬 运,通 路:CO1->A1、CO1->GM
示 例:Mmad含 有 矩 阵 乘 偏 置,左 矩 阵 和 右 矩 阵 的 数 据 类 型 为int8_t,结 果 矩 阵 的 数 据 类 型 为int32_t。量 化 模 式DEQF16,Scalar量 化 参 数 为2.0,将Mmad计 算 出 的 结 果 由int32_t量 化 成half并 搬 出。完 整 算 子 样 例 参 考:随 路Scalar量 化 样 例。
Text// Scalar量 化,量 化 参 数 为2.0 float quantScalar = 2.0; uint64_t deqScalar = static_cast<uint64_t>(*reinterpret_cast<int32_t*>(&quantScalar)); // 将 量 化 参 数 的 标 量 写 入 寄 存 器,供 后 续DataCopy指 令 使 用 AscendC::SetFixpipePreQuantFlag(deqScalar); // 创 建DataCopy的 参 数 AscendC::DataCopyCO12DstParams intriParams; intriParams.nSize = n; intriParams.mSize = m; intriParams.srcStride = CeilAlign(m, CUBE_BLOCK); intriParams.dstStride = n; intriParams.quantPre = QuantMode_t::DEQF16; intriParams.reluPre = 1; // 开 启ReLU intriParams.nz2ndEn = true; // 开 启NZ2ND格 式 转 换 // 根 据intriParams中 的 参 数,执 行 最 终 的 数 据 搬 运 AscendC::DataCopy(cGM, cLocal, intriParams);结 果 示 例 如 下:
Text输 入 数 据(Fm,shape为[1, 4, 4, 32],数 据 类 型 为int8_t): [[[[ 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 3 3 3 3 3 3 3 3 4 4 4 4 4 4 4] ... [12 12 13 13 13 13 13 13 13 13 14 14 14 14 14 14 14 14 15 15 15 15 15 15 15 15 16 16 16 16 16 16]] [[16 16 17 17 17 17 17 17 17 17 18 18 18 18 18 18 18 18 19 19 19 19 19 19 19 19 19 20 20 20 20 20] ... [28 28 28 28 29 29 29 29 29 29 29 29 30 30 30 30 30 30 30 30 31 31 31 31 31 31 31 31 32 32 32 32]] [[32 32 32 32 33 33 33 33 33 33 33 33 34 34 34 34 34 34 34 34 35 35 35 35 35 35 35 35 36 36 36 36] ... [44 44 44 44 44 45 45 45 45 45 45 45 45 46 46 46 46 46 46 46 46 46 47 47 47 47 47 47 47 47 48 48]] [[48 48 48 48 48 48 49 49 49 49 49 49 49 49 50 50 50 50 50 50 50 50 51 51 51 51 51 51 51 51 52 52] ... [60 60 60 60 60 60 60 61 61 61 61 61 61 61 61 62 62 62 62 62 62 62 62 63 63 63 63 63 63 63 63 64]]]] 输 入 数 据(Weight,shape为[1, 2, 2, 128, 32],数 据 类 型 为int8_t): [[[[[1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1] ... [1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1]]]]] 输 出 数 据(DstL0c,shape为[8, 16, 32],数 据 类 型 为int32_t): [[[1572,1572,1572,1572,1572,1572,1572,1572,1572,1572,1572,1572,1572,1572,1572,1572], [2078,2078,2078,2078,2078,2078,2078,2078,2078,2078,2078,2078,2078,2078,2078,2078], [2582,2582,2582,2582,2582,2582,2582,2582,2582,2582,2582,2582,2582,2582,2582,2582], [3592,3592,3592,3592,3592,3592,3592,3592,3592,3592,3592,3592,3592,3592,3592,3592], [4097,4097,4097,4097,4097,4097,4097,4097,4097,4097,4097,4097,4097,4097,4097,4097], [4602,4602,4602,4602,4602,4602,4602,4602,4602,4602,4602,4602,4602,4602,4602,4602], [5612,5612,5612,5612,5612,5612,5612,5612,5612,5612,5612,5612,5612,5612,5612,5612], [6116,6116,6116,6116,6116,6116,6116,6116,6116,6116,6116,6116,6116,6116,6116,6116], [6622,6622,6622,6622,6622,6622,6622,6622,6622,6622,6622,6622,6622,6622,6622,6622], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], ... 输 出 数 据(DstGm,shape为[8, 9, 32],数 据 类 型 为half): [[[ 786. 786. 786. 786. 786. 786. 786. 786. 786. 786. 786. 786. 786. 786. 786. 786.] ... [1039. 1039. 1039. 1039. 1039. 1039. 1039. 1039. 1039. 1039. 1039. 1039. 1039. 1039. 1039. 1039.] ... [1291. 1291. 1291. 1291. 1291. 1291. 1291. 1291. 1291. 1291. 1291. 1291. 1291. 1291. 1291. 1291.] ... [1796. 1796. 1796. 1796. 1796. 1796. 1796. 1796. 1796. 1796. 1796. 1796. 1796. 1796. 1796. 1796.] ... [2048. 2048. 2048. 2048. 2048. 2048. 2048. 2048. 2048. 2048. 2048. 2048. 2048. 2048. 2048. 2048.] ... [2300. 2300. 2300. 2300. 2300. 2300. 2300. 2300. 2300. 2300. 2300. 2300. 2300. 2300. 2300. 2300.] ... [2806. 2806. 2806. 2806. 2806. 2806. 2806. 2806. 2806. 2806. 2806. 2806. 2806. 2806. 2806. 2806.] ... [3058. 3058. 3058. 3058. 3058. 3058. 3058. 3058. 3058. 3058. 3058. 3058. 3058. 3058. 3058. 3058.] ... [3312. 3312. 3312. 3312. 3312. 3312. 3312. 3312. 3312. 3312. 3312. 3312. 3312. 3312. 3312. 3312.] ...示 例:Mmad含 有 矩 阵 乘 偏 置,左 矩 阵 和 右 矩 阵 的 数 据 类 型 为int8_t,结 果 矩 阵 的 数 据 类 型 为int32_t。量 化 模 式VDEQF16,Tensor量 化,将Mmad计 算 出 的 结 果 由int32_t量 化 成half并 搬 出。完 整 算 子 样 例 参 考:随 路Tensor量 化 样 例。
Text// CeilAlign定 义 如 下 __aicore__ inline uint16_t CeilAlign(uint16_t numerator, uint16_t denominator) { return (numerator + denominator - 1) / denominator * denominator; } // 将GM中 的 量 化 数 据 (quantAlphaGM) 拷 贝 到C1(quantAlphaTensor) uint16_t burstLen = CeilAlign(n * sizeof(uint64_t), 128) / AscendC::ONE_BLK_SIZE; AscendC::DataCopyParams intriParams{ 1, burstLen, 0, 0 }; AscendC::DataCopy(quantAlphaTensor, quantAlphaGM, intriParams); // 设 置 同 步,确 保 量 化 数 据 拷 贝 到C1后,执 行 后 续DataCopy指 令 AscendC::SetFlag<AscendC::HardEvent::MTE2_FIX>(EVENT_ID0); AscendC::WaitFlag<AscendC::HardEvent::MTE2_FIX>(EVENT_ID0); // 将C1中 的 量 化 数 据(quantAlphaTensor)拷 贝 到C2PIPE2GM(fbTensor) uint16_t fbufBurstLen = CeilAlign(deqDataSize, 128) / 128; AscendC::DataCopyParams dataCopyParams(1, fbufBurstLen, 0, 0); AscendC::DataCopy(fbTensor, quantAlphaTensor, dataCopyParams); // 将 量 化 参 数 数 据 写 入 寄 存 器,供 后 续DataCopy指 令 使 用 AscendC::SetFixPipeConfig(fbTensor); // 创 建DataCopy的 参 数, AscendC::DataCopyCO12DstParams intriParams; intriParams.nSize = CeilAlign(n, CUBE_BLOCK); intriParams.mSize = m; intriParams.srcStride = CeilAlign(m, CUBE_BLOCK); intriParams.dstStride = m * C0_SIZE / AscendC::ONE_BLK_SIZE; // C0_SIZE = 32 intriParams.quantPre = QuantMode_t::VDEQF16; intriParams.reluPre = 1; // 开 启ReLU // 根 据intriParams中 的 参 数,执 行 最 终 的 数 据 搬 运 AscendC::DataCopy(cGM, cLocal, intriParams);结 果 示 例 如 下:
Text输 入 数 据(Fm,shape为[1, 4, 4, 32],数 据 类 型 为int8_t): [[[[ 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 3 3 3 3 3 3 3 3 4 4 4 4 4 4 4] ... [12 12 13 13 13 13 13 13 13 13 14 14 14 14 14 14 14 14 15 15 15 15 15 15 15 15 16 16 16 16 16 16]] [[16 16 17 17 17 17 17 17 17 17 18 18 18 18 18 18 18 18 19 19 19 19 19 19 19 19 19 20 20 20 20 20] ... [28 28 28 28 29 29 29 29 29 29 29 29 30 30 30 30 30 30 30 30 31 31 31 31 31 31 31 31 32 32 32 32]] [[32 32 32 32 33 33 33 33 33 33 33 33 34 34 34 34 34 34 34 34 35 35 35 35 35 35 35 35 36 36 36 36] ... [44 44 44 44 44 45 45 45 45 45 45 45 45 46 46 46 46 46 46 46 46 46 47 47 47 47 47 47 47 47 48 48]] [[48 48 48 48 48 48 49 49 49 49 49 49 49 49 50 50 50 50 50 50 50 50 51 51 51 51 51 51 51 51 52 52] ... [60 60 60 60 60 60 60 61 61 61 61 61 61 61 61 62 62 62 62 62 62 62 62 63 63 63 63 63 63 63 63 64]]]] 输 入 数 据(Weight,shape为[1, 2, 2, 128, 32],数 据 类 型 为int8_t): [[[[[1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1] ... [1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1]]]]] 输 入 数 据(Quant,shape为[128],数 据 类 型 为float): [0.1 0.01 0.1 0.01 ... 0.1 0.01 0.1 0.01] 输 出 数 据(DstL0c,shape为[8, 16, 32],数 据 类 型 为int32_t): [[[1572,1572,1572,1572,1572,1572,1572,1572,1572,1572,1572,1572,1572,1572,1572,1572], [2078,2078,2078,2078,2078,2078,2078,2078,2078,2078,2078,2078,2078,2078,2078,2078], [2582,2582,2582,2582,2582,2582,2582,2582,2582,2582,2582,2582,2582,2582,2582,2582], [3592,3592,3592,3592,3592,3592,3592,3592,3592,3592,3592,3592,3592,3592,3592,3592], [4097,4097,4097,4097,4097,4097,4097,4097,4097,4097,4097,4097,4097,4097,4097,4097], [4602,4602,4602,4602,4602,4602,4602,4602,4602,4602,4602,4602,4602,4602,4602,4602], [5612,5612,5612,5612,5612,5612,5612,5612,5612,5612,5612,5612,5612,5612,5612,5612], [6116,6116,6116,6116,6116,6116,6116,6116,6116,6116,6116,6116,6116,6116,6116,6116], [6622,6622,6622,6622,6622,6622,6622,6622,6622,6622,6622,6622,6622,6622,6622,6622], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], ... 输 出 数 据(DstGm,shape为[8, 9, 32],数 据 类 型 为half): [[157.1 15.71 157.1 15.71 157.1 15.71 157.1 15.71 157.1 15.71 157.1 15.71 157.1 15.71 157.1 15.71] ... [207.8 20.77 207.8 20.77 207.8 20.77 207.8 20.77 207.8 20.77 207.8 20.77 207.8 20.77 207.8 20.77] ... [258.2 25.81 258.2 25.81 258.2 25.81 258.2 25.81 258.2 25.81 258.2 25.81 258.2 25.81 258.2 25.81] ... [359. 35.9 359. 35.9 359. 35.9 359. 35.9 359. 35.9 359. 35.9 359. 35.9 359. 35.9 ] ... [409.5 40.94 409.5 40.94 409.5 40.94 409.5 40.94 409.5 40.94 409.5 40.94 409.5 40.94 409.5 40.94] ... [460. 46. 460. 46. 460. 46. 460. 46. 460. 46. 460. 46. 460. 46. 460. 46. ] ... [561. 56.1 561. 56.1 561. 56.1 561. 56.1 561. 56.1 561. 56.1 561. 56.1 561. 56.1 ] ... [611.5 61.12 611.5 61.12 611.5 61.12 611.5 61.12 611.5 61.12 611.5 61.12 611.5 61.12 611.5 61.12] ...针 对Atlas 200I/500 A2 推 理 产 品,随 路 格 式 转 换 数 据 搬 运,通 路:CO1->GM。
示 例:Mmad含 有 矩 阵 乘 偏 置,左 矩 阵 和 右 矩 阵 的 数 据 类 型 为int8_t,结 果 矩 阵 的 数 据 类 型 为int32_t。量 化 模 式DEQF16,scalar量 化 参 数 为0.5,将Mmad计 算 出 的 结 果 由int32_t量 化 成half并 搬 出。
Text#ifdef ASCENDC_CPU_DEBUG #include "tikicpulib.h" #endif #include "kernel_operator.h" #include "../../instrs/common_utils/register_utils.h" template <typename dst_T, typename fmap_T, typename weight_T, typename dstCO1_T> class KernelCubeDataCopy{ public: __aicore__ inline KernelCubeDataCopy(uint16_t CoutIn, uint8_t dilationHIn, uint8_t dilationWIn, QuantMode_t deqModeIn) { // ceiling of 16 Cout = CoutIn; dilationH = dilationHIn; dilationW = dilationWIn; C0 = 32 / sizeof(fmap_T); C1 = channelSize / C0; coutBlocks = (Cout + 16 - 1) / 16; ho = H - dilationH * (Kh - 1); wo = W - dilationW * (Kw - 1); howo = ho * wo; howoRound = ((howo + 16 - 1) / 16) * 16; featureMapA1Size = C1 * H * W * C0; // shape: [C1, H, W, C0] weightA1Size = C1 * Kh * Kw * Cout * C0; // shape: [C1, Kh, Kw, Cout, C0] featureMapA2Size = howoRound * (C1 * Kh * Kw * C0); weightB2Size = (C1 * Kh * Kw * C0) * coutBlocks * 16; m = howo; k = C1 * Kh * Kw * C0; n = Cout; biasSize = Cout; // shape: [Cout] dstSize = coutBlocks * howo * 16; // shape: [coutBlocks, howo, 16] dstCO1Size = coutBlocks * howoRound * 16; fmRepeat = featureMapA2Size / (16 * C0); weRepeat = weightB2Size / (16 * C0); deqMode = deqModeIn; } __aicore__ inline void Init(__gm__ uint8_t* fmGm, __gm__ uint8_t* weGm, __gm__ uint8_t* biasGm, __gm__ uint8_t* deqGm, __gm__ uint8_t* eleWiseGm, __gm__ uint8_t* dstGm) { fmGlobal.SetGlobalBuffer((__gm__ fmap_T*)fmGm); weGlobal.SetGlobalBuffer((__gm__ weight_T*)weGm); biasGlobal.SetGlobalBuffer((__gm__ dstCO1_T*)biasGm); deqGlobal.SetGlobalBuffer((__gm__ uint64_t*)deqGm); dstGlobal.SetGlobalBuffer((__gm__ dst_T*)dstGm); eleWiseGlobal.SetGlobalBuffer((__gm__ half*)eleWiseGm); pipe.InitBuffer(inQueueFmA1, 1, featureMapA1Size * sizeof(fmap_T)); pipe.InitBuffer(inQueueFmA2, 1, featureMapA2Size * sizeof(fmap_T)); pipe.InitBuffer(inQueueWeB1, 1, weightA1Size * sizeof(weight_T)); pipe.InitBuffer(inQueueWeB2, 1, weightB2Size * sizeof(weight_T)); pipe.InitBuffer(inQueueBiasA1, 1, biasSize * sizeof(dstCO1_T)); pipe.InitBuffer(inQueueDeqA1, 1, dstCO1Size * sizeof(uint64_t)); pipe.InitBuffer(inQueueDeqFB, 1, dstCO1Size * sizeof(uint64_t)); pipe.InitBuffer(outQueueCO1, 1, dstCO1Size * sizeof(dstCO1_T)); pipe.InitBuffer(inQueueC1, 1, dstSize * sizeof(half)); } __aicore__ inline void Process() { CopyIn(); Split(); Compute(); CopyOut(); } private: __aicore__ inline void CopyIn() { AscendC::LocalTensor<fmap_T> featureMapA1 = inQueueFmA1.AllocTensor<fmap_T>(); AscendC::LocalTensor<weight_T> weightB1 = inQueueWeB1.AllocTensor<weight_T>(); AscendC::LocalTensor<dstCO1_T> biasA1 = inQueueBiasA1.AllocTensor<dstCO1_T>(); AscendC::DataCopy(featureMapA1, fmGlobal, { 1, static_cast<uint16_t>(featureMapA1Size * sizeof(fmap_T) / 32), 0, 0 }); AscendC::DataCopy(weightB1, weGlobal, { 1, static_cast<uint16_t>(weightA1Size * sizeof(weight_T) / 32), 0, 0 }); AscendC::DataCopy(biasA1, biasGlobal, { 1, static_cast<uint16_t>(biasSize * sizeof(dstCO1_T) / 32), 0, 0 }); inQueueFmA1.EnQue(featureMapA1); inQueueWeB1.EnQue(weightB1); inQueueBiasA1.EnQue(biasA1); } __aicore__ inline void Split() { AscendC::LocalTensor<fmap_T> featureMapA1 = inQueueFmA1.DeQue<fmap_T>(); AscendC::LocalTensor<weight_T> weightB1 = inQueueWeB1.DeQue<weight_T>(); AscendC::LocalTensor<fmap_T> featureMapA2 = inQueueFmA2.AllocTensor<fmap_T>(); AscendC::LocalTensor<weight_T> weightB2 = inQueueWeB2.AllocTensor<weight_T>(); uint8_t padList[] = {0, 0, 0, 0}; // load3dv2 AscendC::LoadData(featureMapA2, featureMapA1, { padList, H, W, channelSize, k, howoRound, 0, 0, 1, 1, Kw, Kh, dilationW, dilationH, false, false, 0 }); // load2d AscendC::LoadData(weightB2, weightB1, { 0, weRepeat, 1, 0, 0, false, 0 }); inQueueFmA2.EnQue<fmap_T>(featureMapA2); inQueueWeB2.EnQue<weight_T>(weightB2); inQueueFmA1.FreeTensor(featureMapA1); inQueueWeB1.FreeTensor(weightB1); } __aicore__ inline void Compute() { AscendC::LocalTensor<fmap_T> featureMapA2 = inQueueFmA2.DeQue<fmap_T>(); AscendC::LocalTensor<weight_T> weightB2 = inQueueWeB2.DeQue<weight_T>(); AscendC::LocalTensor<dstCO1_T> dstCO1 = outQueueCO1.AllocTensor<dstCO1_T>(); AscendC::LocalTensor<dstCO1_T> biasA1 = inQueueBiasA1.DeQue<dstCO1_T>(); // C = A * B + bias // m: 左 矩 阵Height, k: 左 矩 阵Width, n: 右 矩 阵Width AscendC::Mmad(dstCO1, featureMapA2, weightB2, biasA1, { m, n, k, true, 0, false, false, false }); outQueueCO1.EnQue<dstCO1_T>(dstCO1); inQueueFmA2.FreeTensor(featureMapA2); inQueueWeB2.FreeTensor(weightB2); } __aicore__ inline void CopyOut() { AscendC::LocalTensor<dstCO1_T> dstCO1 = outQueueCO1.DeQue<dstCO1_T>(); // 开 启DEQF16量 化,量 化 参 数 设 置 为0.5 float tmp = (float)0.5; // 将float的tmp转 换 成uint64_t的deqScalar uint64_t deqScalar = static_cast<uint64_t>(*reinterpret_cast<int32_t*>(&tmp)); bool nz2ndEn = false; // nz2nd不 开 启 时,nSize必 须 为16的 倍 数 uint16_t nSize = coutBlocks * 16; uint16_t mSize = m; // srcStride必 须 为16的 倍 数 uint16_t srcStride = (m + 16 - 1) / 16 * 16; // nz2nd不 开 启 时,dstStride为burst头 到 头 的 距 离,且 为32B对 齐 uint32_t dstStride = m * sizeof(dst_T) * 16 / 32; if (nz2ndEn) { // nd矩 阵 的 数 量 为1,src_nd_stride与dst_nd_stride填1 AscendC::SetFixpipeNz2ndFlag(1, 1, 1); // nz2nd开 启 时,nSize可 以 不 为16的 倍 数,与Mmad的n保 持 一 致 nSize = n; // nz2nd开 启 时,dstStride表 示 同 一nd矩 阵 的 相 邻 连 续 行 的 间 隔,与n保 持 一 致 dstStride = nSize; }; // 不 开 启relu与channelSplit AscendC::DataCopyCO12DstParams intriParams(nSize, mSize, dstStride, srcStride, deqMode, 0, false, nz2ndEn); // mov l0c to gm, deq scalar quant AscendC::SetFixpipePreQuantFlag(deqScalar); // 设 置 量 化 参 数 AscendC::PipeBarrier<PIPE_FIX>(); AscendC::DataCopy(dstGlobal, dstCO1, intriParams); // // mov l0c to gm, deq tensor quant // // 需 要 额 外 申 请deq tensor的gm空 间,将 值 搬 运 到workA1 // AscendC::LocalTensor<uint64_t> workA1 = inQueueDeqA1.AllocTensor<uint64_t>(); // // deq tensor的size // uint16_t deqSize = 128; // AscendC::DataCopy(workA1, deqGlobal, deqSize); // // deq tensor在fix上 的 地 址 // AscendC::LocalTensor<uint64_t> deqFB = inQueueDeqFB.AllocTensor<uint64_t>(); // // l1->fix, burst_len unit is 128Bytes // uint16_t fbufBurstLen = deqSize / 128; // AscendC::DataCopyParams dataCopyParams(1, fbufBurstLen, 0, 0); // AscendC::DataCopy(deqFB, workA1, dataCopyParams); // // 设 置 量 化tensor // AscendC::SetFixPipeConfig(deqFB); // AscendC::PipeBarrier<PIPE_FIX>(); // // mov l0c to gm, 量 化 操 作 后 开 启ClipRelu操 作 // intriParams.clipReluPre = 1; // // 设 置clip relu的 值 到 寄 存 器 // uint64_t clipReluVal = 0x3c00; // value 1, half // SetFixPipeClipRelu(clipReluVal); // //mov l0c to gm, 量 化 操 作 后,设 置 element-wise 操 作,Add // intriParams.eltWiseOp = 1; // // 需 要 额 外 申 请 element-wise tensor的gm空 间,将 值 搬 到eleWiseTensor // AscendC::LocalTensor<half> eleWiseTensor = inQueueC1.AllocTensor<half>(); // DataCopy(eleWiseTensor, eleWiseGlobal, { 1, static_cast<uint16_t>(sizeof(half) * dst_size / 32), 0, 0 }); // AscendC::PipeBarrier<PIPE_ALL>(); // // 将 存 放element-wise tensor的 地 址 设 置 到 寄 存 器 里 // SetFixPipeAddr(eleWiseTensor, 1); // AscendC::DataCopy(dstGlobal, dstCO1, intriParams); // inQueueDeqA1.FreeTensor(workA1); // inQueueDeqFB.FreeTensor(deqFB); // outQueueCO1.FreeTensor(dstCO1); // inQueueC1.FreeTensor(eleWiseTensor); } private: AscendC::TPipe pipe; // feature map queue AscendC::TQue<AscendC::TPosition::A1, 1> inQueueFmA1; AscendC::TQue<AscendC::TPosition::A2, 1> inQueueFmA2; // weight queue AscendC::TQue<AscendC::TPosition::B1, 1> inQueueWeB1; AscendC::TQue<AscendC::TPosition::B2, 1> inQueueWeB2; // bias queue AscendC::TQue<AscendC::TPosition::A1, 1> inQueueBiasA1; // deq tensor queue AscendC::TQue<AscendC::TPosition::A1, 1> inQueueDeqA1; // fb dst of deq tensor AscendC::TQue<AscendC::TPosition::C2PIPE2GM, 1> inQueueDeqFB; // dst queue AscendC::TQue<AscendC::TPosition::CO1, 1> outQueueCO1; // element-wise tensor AscendC::TQue<AscendC::TPosition::C1, 1> inQueueC1; AscendC::GlobalTensor<fmap_T> fmGlobal; AscendC::GlobalTensor<weight_T> weGlobal; AscendC::GlobalTensor<dst_T> dstGlobal; AscendC::GlobalTensor<uint64_t> deqGlobal; AscendC::GlobalTensor<dstCO1_T> biasGlobal; AscendC::GlobalTensor<half> eleWiseGlobal; uint16_t channelSize = 32; uint16_t H = 4, W = 4; uint8_t Kh = 2, Kw = 2; uint16_t Cout; uint16_t C0, C1; uint8_t dilationH, dilationW; uint16_t coutBlocks, ho, wo, howo, howoRound; uint32_t featureMapA1Size, weightA1Size, featureMapA2Size, weightB2Size, biasSize, dstSize, dstCO1Size; uint16_t m, k, n; uint8_t fmRepeat, weRepeat; QuantMode_t deqMode = QuantMode_t::NoQuant; }; #define KERNEL_CUBE_DATACOPY(dst_type, fmap_type, weight_type, dstCO1_type, CoutIn, dilationHIn, dilationWIn, deqModeIn) \ extern "C" __global__ __aicore__ void cube_datacopy_kernel_##fmap_type(__gm__ uint8_t* fmGm, __gm__ uint8_t* weGm, \ __gm__ uint8_t* biasGm, __gm__ uint8_t* deqGm, __gm__ uint8_t* eleWiseGm, __gm__ uint8_t* dstGm) \ { \ if (g_coreType == AscendC::AIV) { \ return; \ } \ KernelCubeDataCopy<dst_type, fmap_type, weight_type, dstCO1_type> op(CoutIn, dilationHIn, dilationWIn, \ deqModeIn); \ op.Init(fmGm, weGm, biasGm, deqGm, eleWiseGm, dstGm); \ op.Process(); \ } KERNEL_CUBE_DATACOPY(half, int8_t, int8_t, int32_t, 128, 1, 1, QuantMode_t::DEQF16);